
大模子的应用历来受幻觉所扰菊花 流出 国产 porn。
这个幻觉不错指代LLM产生的任何类型的不实:事实不准确、偏见、学问推理失败等等。
——是因为大模子学半天白学了吗?并不是。
近日,来自谷歌和苹果的琢磨标明:AI模子掌抓的知识比施展出来的更多!

琢磨东谈主员在LLM里面示意上检修分类器,以预计与生成输出的真确性有关的多样特征。
扫尾标明LLM的里面气象编码反馈出的真确性信息,比过去意识到的要多得多。
这些真确性信息鸠合在特定的token中,运用这一属性不错显贵擢升检测LLM不实输出的才气。

虽说这种不实检测无法在数据鸠合泛化,但公正是,模子的里面示意可用于预计模子可能犯的不实类型,从而匡助咱们制定缓解不实的计谋。
琢磨揭示了LLM里面编码和外部举止之间的各别:可能编码了正确的谜底,却生成了不正确的谜底。
——浅近来说即是,LLM它知谈,但它不念念告诉你!
LLM在装傻
作家淡薄将要点从以东谈主类为中心的幻觉诠释鼎新到以模子为中心的视角,查验模子的中间激活。
不同于使用RAG或者依赖更高大的LLM judge,本文职责的要点是仅依赖于模子输出的logits、softmax后的概率和荫藏气象的诡计。
不实检测器
第一步是细目真确性信号在LLM中的编码位置。
假定咱们不错探听LLM的里面气象(白盒),但不可探听任何外部资源(搜索引擎或其他LLM)。
配置一个数据集D,由N个问题标签对构成,对于每个问题,指示模子生成响应,从而取得一组预计谜底。
接下来,比拟LLM生成的薪金与正确谜底,从而构建不实检测数据集(这一部可由AI代劳)。
实验遴荐了四个LLM:Mistral-7b,Mistral-7b-instruct-v0.2,Llama3-8b和Llama3-8b-instruct。

作家中式了10个进步不同限度和任务的数据集:TriviaQA、HotpotQA(with/without context)、Natural Questions、Winobias、Winogrande、MNLI、Math、IMDB review sentiment analysis和另一个公正的电影扮装数据集。
实验允许无扫尾地生成响应以模拟推行天下LLM的用法,并决策地解码谜底。
性能缠绵
测量ROC弧线底下积以评估不实检测器,这粗略反馈模子在多个阈值中分别阳性和阴本性况的才气,均衡贤人度(真阳性率)和特异性(假阳性率)。
不实检测方法
Majority:永恒预计检修数据中最频繁的标签。
团员概率/logits:从之前的琢磨中中式几种方法,包括诡计这些值的最小值、最大值或平均值。
P(True):通过指示条款LLM评估其生成的正确性时。
Probing:在模子的中间激活上检修一个小分类器,以预计已治理文本的特征,这里使用线性探伤分类器对静态token进行不实检测。
作家合计,现存方法忽略了一个重要的细节:用于不实检测token的遴荐。
琢磨者宽泛只关心临了生成的token或取平均值,干系词,由于LLM一般会生成长体式响应,这种作念法可能会错过遑急的部分。
本文中,作家关心示意实在谜底的token(EXACT ANSWER TOKENS),它代表了生成的响应中最特风趣风趣的部分。

这里将EXACT ANSWER TOKENS界说为,要是修改则会改造谜底正确性的token。
履行中,作家使用配置好的instruct模子代劳,来索求实在谜底。之后,通过浅近的搜索进程细目对应的token。
要点关心4个特定token:第一个实在谜底的token过火前一个token、临了一个实在谜底token过火后一个token。
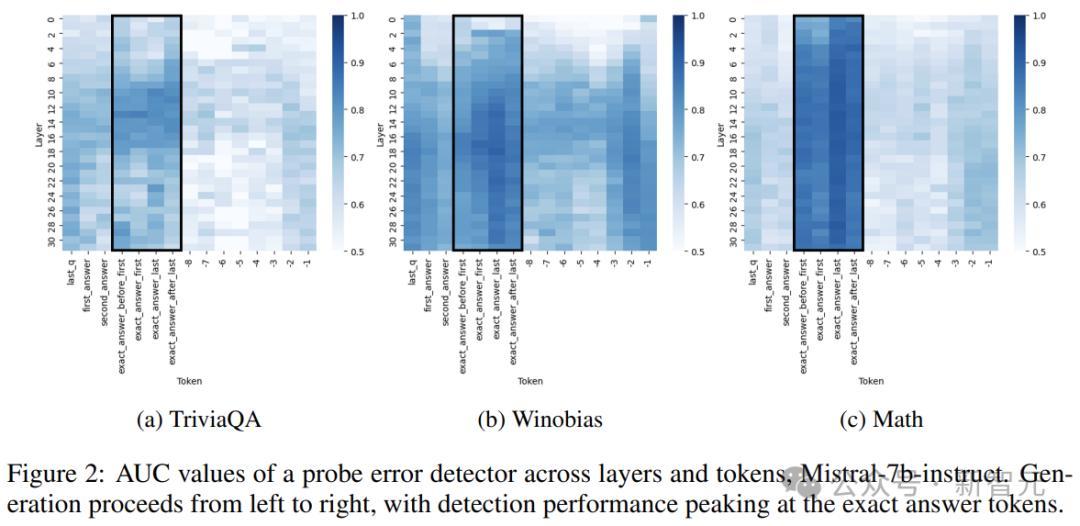
作家庸俗分析了层和token遴荐对分类器的激活索求的影响,通过系统地探伤模子的总共层,从临了一个问题token运转,一直到最毕生成的token。
上图暴露了Mistral-7b-Struct中各个层和token对于探伤的AUC缠绵。天然一些数据集似乎更容易进行不实预计,但所迥殊据集皆施展出一致的真确性编码阵势,中后期层宽泛会产生最灵验的探伤扫尾。
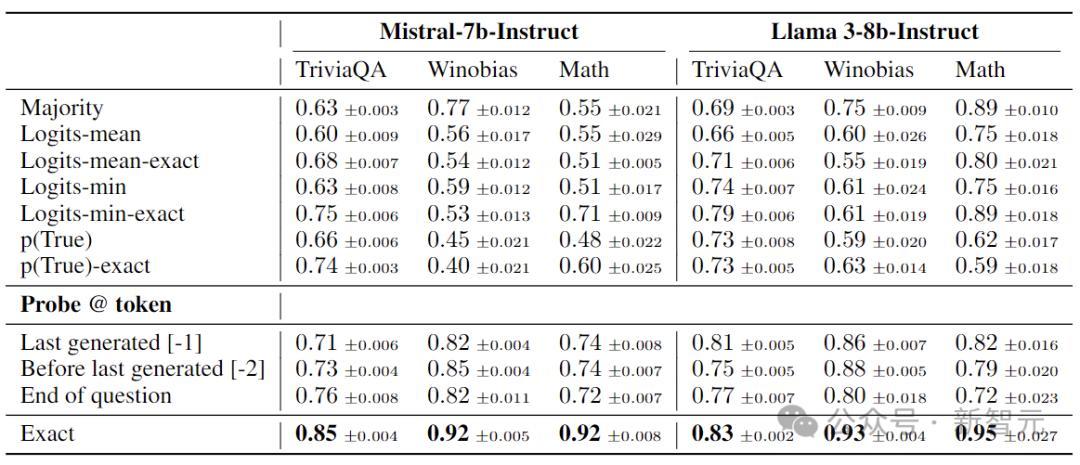
通过比拟使用和不使用EXACT ANSWER TOKENS的性能,来评估多样不实检测方法,上表展示了三个代表性数据集上的AUC。
不同任务中的泛化
了解不实检测器在不同任务中的泛化才气,对于实质应用规律至关遑急。

上图(a)暴露了Mistral-7b-instruct的泛化扫尾,大于0.5的值示意泛化顺利。乍一看,大多数热图值杰出了0.5,似乎任务之间存在一定进程的泛化。
干系词事实上,大部分性能不错通过基于logit的真度检测来竣事。图(b)暴露了从最强的基于Logit的基线(Logit-min-exact)中减去扫尾后的疏浚热图。
这示意检测器的泛化进程很少杰出仅依赖Logit所能达到的着力。是以,泛化并不源于真确性的里面编码,而是反馈了如故通过logits等外部特征探听的信息。
av收藏
经过检修的探伤分类器不错预计不实,但其泛化才气只发生在需要相似手段的任务(如事实检索)中。
对于波及不同手段的任务,举例情愫分析,探伤分类器与基于logit的不细目性预计器着力差未几。
不实类型琢磨
在细目了不实检测的局限性,并琢磨了不同任务的不实编码有何不同之后,作家长远琢磨了单个任务中的不实,凭据模子对重叠样本的响应付其不实进行分类。
比如,连接生成的疏浚不实与偶尔生成的不实属于不同类别。
琢磨东谈主员在T = 30的温度配置下,对数据鸠合的每个样本进行采样,然后分析谜底的扫尾漫衍。
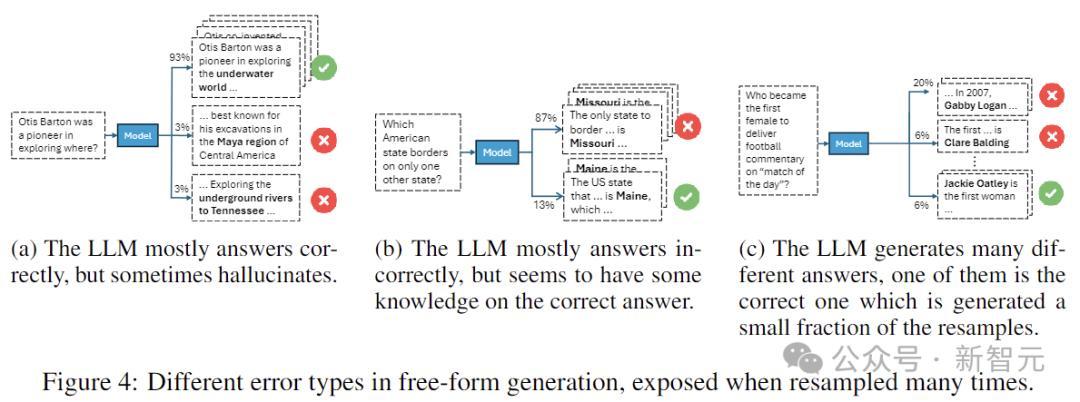
上图展示了三种代表性的不实类型:
图(4a)中,模子宽泛会给出正确的谜底,但偶尔会出错,这意味着存在正确的信息,但采样可能会导致不实。
图(4b)中,模子往往犯相同的不实,但仍保留了一些知识。
图(4c)中,模子生成了无数不实的谜底,举座置信度较低。
分类的圭表有三个:生成的不同谜底的数目,正确谜底的频率,以及最常见的不实谜底的频率。

上表暴露了总共模子的测试逼近果。扫尾标明,不错从决策解码的中间示意中预计不实类型。
检测正确谜底
模子的这种里面真确性如安在响应生成进程中与其外部举止保持一致?
作家使用经过不实检测检修的探伤器,从并吞问题的30个响应中遴荐一个谜底,凭据所选谜底揣测模子的准确性。
要是这种准确性与传统解码方法(如决策解码)莫得显贵各别,则标明LLM的真确性里面示意与其外部举止一致。
实验在TriviaQA、Winobias和Math上进行,遴荐probe评估的正确性概率最高的谜底。这里比拟了三个基线:决策解码;从30个候选谜底中迅速遴荐;遴荐生成的最频繁的谜底。

扫尾如上图所示,总体而言,使用探针遴荐谜底不错擢升LLM总共查验任务的准确性。然而,革命的进程因不实类型而异。
探针不错灵验地识别正确谜底的事实标明,LLM的里面编码与其外部举止之间存在紧要脱节:即使模子编码了哪个谜底是正确的信息菊花 流出 国产 porn,它在履行中仍然可能生成不实的谜底。